Apache Kafka

Apache Kafka is an open-source platform designed for building real-time data pipelines and streaming applications. It was originally developed at LinkedIn and is now part of the Apache Software Foundation.
Kafka is a system that lets different applications send, receive, and store streams of data in real time.
Think of it as: A high-speed messaging system + data streaming backbone for modern distributed systems.
Why we use Kafka?
• To handle real-time data streaming
• To connect different systems (decoupling services)
• To build event-driven architectures
• To process high-volume data pipelines
• To collect and process logs, metrics, and events
When should you use Kafka?
Kafka is a good fit when:
• You need real-time data processing
• You are building microservices architecture
• You need to handle high-throughput event streams
• You want reliable message delivery at scale
• You are processing logs, clickstreams, IoT data
Not ideal when:
• Your system is small/simple
• You only need basic messaging
• You require strict request/response workflows
• You don’t need event streaming or persistence
Key features of Kafka
• High throughput (millions of messages/sec)
• Scalable distributed architecture
• Durable message storage (disk-based log)
• Fault tolerance via replication
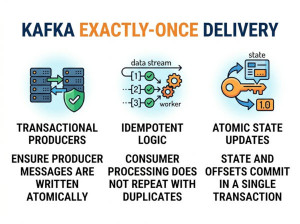
• Publish–subscribe messaging model
• Real-time stream processing support
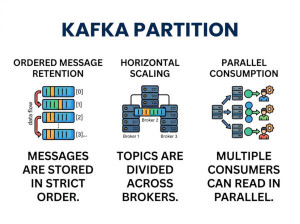
• Horizontal scalability
Key components of Apache Kafka
• Producer: Sends messages to Kafka
• Consumer: Reads messages from Kafka
• Topic: Logical channel where messages are stored
• Partition: Splits topics for scalability and parallelism
• Broker: Kafka server that stores and serves data
• Cluster: Group of brokers working together
• ZooKeeper (legacy): Used for coordination in older versions (replaced in newer Kafka with KRaft mode)
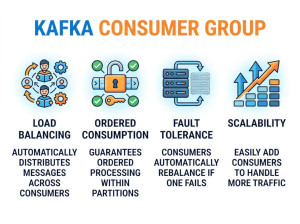
• Consumer Group: Group of consumers sharing workload
How Kafka works (basic flow)?
• Producer sends data to Topic
• Kafka stores data in partitions
• Consumers read data from topics
• Data remains stored for a configurable time
Advantages
• Extremely fast and scalable
• Handles massive real-time data streams
• Reliable fault-tolerant system
• Decouples systems (loose coupling)
• Supports event-driven architecture
• Persistent message storage (replay capability)
Disadvantages
• Complex to set up and manage
• Requires careful tuning and monitoring
• Not ideal for simple use cases
• Learning curve for distributed concepts
• Operational overhead in production
Alternatives
RabbitMQ
RabbitMQ is a traditional messaging system (better for simpler queues)
Apache Pulsar
Similar to Kafka, more flexible architecture
Amazon Kinesis
Managed cloud streaming platform
Google Pub/Sub
Fully managed event delivery system