Redis

Redis is an open-source, in-memory data store often used as a database, cache, and message broker. It stores data in RAM instead of disk, which makes it extremely fast. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
Redis is an open-source, networked, in-memory, key-value data store with optional durability. It is written in ANSI C. The development of Redis has been sponsored by Pivotal since May 2013; before that, it was sponsored by VMware. According to the monthly ranking by DB-Engines.com, Redis is the most popular key-value store. The name Redis means REmote DIctionary Server.
It's a "NoSQL" key-value data store. More precisely, it is a data structure server. Not like MongoDB (which is a disk-based document store), though MongoDB could be used for similar key/value use cases. The closest analog is probably to think of Redis as Memcached, but with built-in persistence (snapshotting or journaling to disk) and more datatypes.
Why use Redis?
You’d use Redis when speed matters a lot:
• Caching frequently accessed data
• Reducing load on your main database
• Managing sessions (e.g., logged-in users)
• Real-time features (chat, notifications)
When should you use it?
Redis is a great fit when:
• You need ultra-fast reads/writes
• You’re building real-time applications
• You want to cache database queries
• You need temporary or short-lived data
• You need pub/sub messaging
Less ideal when:
• You need large persistent datasets (RAM is limited/expensive)
• You require complex relational queries (use SQL DB instead)
Key components / data structures
Redis is powerful because of its built-in data types:
• Strings → basic key-value
• Lists → ordered collections
• Sets → unique unordered values
• Sorted Sets → ranked data (e.g., leaderboards)
• Hashes → objects (like JSON fields)
• Streams → event/log data
Key features
• In-memory storage (very fast)
• Optional persistence (snapshotting, AOF)
• Pub/Sub messaging system
• Atomic operations
• Replication and clustering
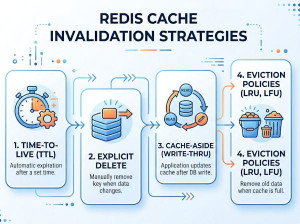
• TTL (expiration) for keys
• Lua scripting support
Advantages
• Extremely fast (microsecond latency)
• Supports rich data structures
• Great for scaling performance
• Easy to integrate with most languages
• Built-in replication and high availability
Disadvantages
• Data stored in RAM → expensive at scale
• Risk of data loss if not configured for persistence
• Not ideal for complex queries or relationships
• Requires careful memory management
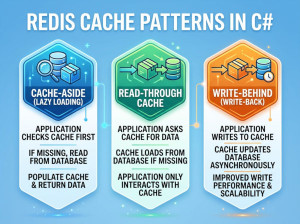
Common use cases
• Caching layer (most popular use)
• Session store (user login data)
• Real-time analytics
• Leaderboards in games
• Message queues / event streaming
Alternatives
1. Memcached
• Simpler, purely for caching
• Less feature-rich than Redis
2. MongoDB
• Persistent document database
• Not as fast as Redis but more flexible
3. Apache Kafka
• Better for large-scale event streaming
• More complex than Redis Pub/Sub
4. Amazon ElastiCache
• Managed Redis/Memcached in the cloud
Redis Supported languages
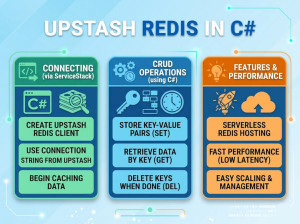
Many languages have Redis bindings, including: ActionScript, C, C++, C#, Clojure, Common Lisp, Dart, Erlang, Go, Haskell, Haxe, Io, Java, JavaScript (Node.js), Lua, Objective-C, Perl, PHP, Pure Data, Python, R, Ruby, Scala, Smalltalk and Tcl.
Redis Data models
In its outer layer, the Redis data model is a dictionary which maps keys to values. One of the main differences between Redis and other structured storage systems is that Redis supports not only strings, but also abstract data types:
• Lists of strings
• Sets of strings (collections of non-repeating unsorted elements)
• Sorted sets of strings (collections of non-repeating elements ordered by a floating-point number called score)
• Hashes where keys and values are strings
The type of a value determines what operations (called commands) are available for the value itself. Redis supports high-level, atomic, server-side operations like intersection, union, and difference between sets and sorting of lists, sets and sorted sets.
Redis Persistence
Redis typically holds the whole dataset in memory. Versions up to 2.4 could be configured to use what they refer to as virtual memory in which some of the dataset is stored on disk, but this feature is deprecated. Persistence is now reached in two different ways: one is called snapshotting, and is a semi-persistent durability mode where the dataset is asynchronously transferred from memory to disk from time to time, written in RDB dump format. Since version 1.1 the safer alternative is AOF, an append-only file (a journal) that is written as operations modifying the dataset in memory are processed. Redis is able to rewrite the append-only file in the background in order to avoid an indefinite growth of the journal.
Redis Replication
Redis supports master-slave replication. Data from any Redis server can replicate to any number of slaves. A slave may be a master to another slave. This allows Redis to implement a single-rooted replication tree. Redis slaves are writable, permitting intentional and unintentional inconsistency between instances. The Publish/Subscribe feature is fully implemented, so a client of a slave may SUBSCRIBE to a channel and receive a full feed of messages PUBLISHed to the master, anywhere up the replication tree. Replication is useful for read (but not write) scalability or data redundancy.
Performance of Redis
When the durability of data is not needed, the in-memory nature of Redis allows it to perform extremely well compared to database systems that write every change to disk before considering a transaction committed. There is no notable speed difference between write and read operations. Redis operates as a single process and single-threaded. Therefore a single Redis instance cannot utilize parallel execution of tasks e.g. stored procedures (Lua scripts).
Redis Clustering
The Redis project has a cluster specification, but the cluster feature is currently in Alpha stage. According to a news post by Redis creator Sanfilippo, the first production version of Redis cluster (planned for beta release at end of 2013), will support automatic partitioning of the key space and hot resharding, but will support only single key operations. In future Redis Cluster is planned to support up to 1000 nodes, fault tolerance with heartbeat and failure detection, incremental versioning ("epochs") to prevent conflicts, slave election and promotion to master, and publish/subscribe between all cluster nodes.