Vector Databases: Architecture, Use Cases, Features and Advantages

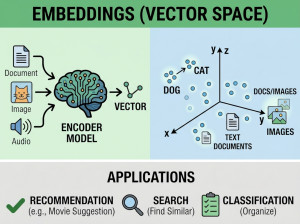
A vector database is a specialized database designed to store, index, and search high-dimensional vector embeddings for semantic similarity retrieval in AI applications.
Vector databases store numerical representations of data called embeddings, which are generated by machine learning models from text, images, audio, or other content. Instead of traditional exact-match searches, vector databases perform similarity searches to find items that are semantically related. They use Approximate Nearest Neighbor (ANN) algorithms and vector indexing techniques to retrieve relevant vectors efficiently at scale. Vector databases are a core component of modern AI systems such as Retrieval-Augmented Generation (RAG), recommendation engines, semantic search, and multimodal AI applications. They enable Large Language Models (LLMs) to retrieve contextual information quickly and accurately.
Why We Use Vector Databases?
We use vector databases because traditional relational databases are not optimized for semantic similarity search.
Key reasons include:
• Fast similarity search across millions or billions of vectors
• Efficient storage of embedding representations
• Better semantic understanding than keyword search
• Scalability for AI and machine learning systems
• Support for real-time retrieval in RAG pipelines
• Reduced latency in AI search applications
• Improved recommendation and personalization systems
When Should We Use Vector Databases?
Best Use Cases for Vector Databases
• Retrieval-Augmented Generation (RAG)
• Semantic document search
• AI chatbots and assistants
• Recommendation systems
• Image similarity search
• Audio and video retrieval
• Fraud detection
• Personalized search engines
• Enterprise knowledge systems
• E-commerce product recommendations
• Multimodal AI systems
When NOT to Use Vector Databases?
• Simple relational data storage
• Exact-match transactional systems
• Traditional banking transactions
• Small datasets with no semantic search needs
• Applications requiring strong ACID relational operations only
• Cases where keyword search is sufficient
• Highly structured analytical workloads better suited for SQL databases
Key Components of a Vector Database
| Component | Description |
|---|---|
| Embedding Model | Converts data into numerical vector embeddings. |
| Vector Storage | Stores high-dimensional vectors efficiently. |
| Indexing Engine | Builds indexes for fast nearest-neighbor search. |
| Similarity Search Engine | Finds vectors closest to a query vector. |
| Metadata Storage | Stores labels, tags, filters, and document metadata. |
| Query Processor | Handles vector search requests and filtering logic. |
| ANN Algorithms | Optimizes approximate nearest neighbor retrieval. |
Key Features of Vector Databases
| Feature | Benefit |
|---|---|
| Semantic Search | Finds meaning-based results instead of exact matches. |
| High-Dimensional Storage | Handles complex embeddings efficiently. |
| Approximate Nearest Neighbor Search | Enables fast retrieval at large scale. |
| Scalability | Supports millions or billions of vectors. |
| Metadata Filtering | Combines semantic search with structured filtering. |
| Real-Time Retrieval | Supports low-latency AI applications. |
| Hybrid Search | Combines vector and keyword search. |
Implementation Examples of Vector Databases
Example 1: RAG System
Workflow:
• Documents are converted into embeddings.
• Embeddings are stored in a vector database.
• User query is embedded.
• Similar vectors are retrieved.
• Retrieved context is passed to the LLM.
Technologies:
• OpenAI Embeddings
• Pinecone
• LangChain
• GPT models
Example 2: E-Commerce Recommendation Engine
Workflow:
• Product descriptions are embedded.
• Similar products are indexed.
• Customer interactions generate query embeddings.
• Vector search returns related products.
Benefits:
• Better personalization
• Improved product discovery
• Higher conversion rates
Example 3: Image Similarity Search
Workflow:
• Images are converted into feature embeddings using CNNs or vision transformers.
• Vectors are indexed.
• User uploads an image.
• Similar images are retrieved based on vector similarity.
Advantages of Vector Databases
| Advantage | Explanation |
|---|---|
| Fast Semantic Search | Retrieves semantically related content quickly. |
| Scalable Retrieval | Handles massive embedding datasets efficiently. |
| AI Optimization | Built specifically for machine learning workloads. |
| Improved Recommendations | Enhances personalization systems. |
| Low Latency | Supports real-time AI applications. |
| Flexible Search | Supports semantic, hybrid, and filtered search. |
Disadvantages of Vector Databases
| Disadvantage | Explanation |
|---|---|
| Infrastructure Complexity | Requires embedding pipelines and indexing systems. |
| Memory Usage | Large vector indexes consume significant memory. |
| Approximate Results | ANN search may sacrifice some accuracy for speed. |
| Operational Cost | Cloud vector storage can become expensive at scale. |
| Embedding Dependency | Search quality depends heavily on embedding quality. |
| Limited Relational Features | Not ideal for complex relational transactions. |
Most Used Vector Databases
Popular Vector Databases:
• Pinecone
• FAISS
• Weaviate
• Milvus
• Qdrant
• ChromaDB
• pgvector
• Elasticsearch Vector Search
• Vespa
• Redis Vector Search
Comparison of Popular Vector Databases
| Vector Database | Type | Open Source | Managed Cloud | Best For | Main Strength | Main Limitation |
|---|---|---|---|---|---|---|
| Pinecone | Managed Vector DB | No | Yes | Production RAG systems | Fully managed and scalable | Higher cost at scale |
| FAISS | Library | Yes | No | Research and local vector search | Extremely fast ANN search | No built-in distributed infrastructure |
| Weaviate | Vector Database | Yes | Yes | Hybrid semantic search | GraphQL and hybrid search support | More operational complexity |
| Milvus | Distributed Vector DB | Yes | Yes | Large-scale enterprise AI | Highly scalable distributed architecture | Complex deployment |
| Qdrant | Vector Database | Yes | Yes | Filtering-heavy AI systems | Strong metadata filtering | Smaller ecosystem than FAISS |
| ChromaDB | Embedded Vector DB | Yes | Limited | Prototyping and local AI apps | Simple developer experience | Limited enterprise scalability |
| pgvector | PostgreSQL Extension | Yes | Depends on PostgreSQL provider | Apps already using PostgreSQL | SQL + vector search together | Not as optimized as specialized vector DBs |
| Elasticsearch | Search Engine | Yes | Yes | Hybrid keyword + vector search | Mature search ecosystem | Complex tuning for vector workloads |
| Redis Vector Search | In-Memory Database | Yes | Yes | Ultra-low latency systems | Very fast retrieval speed | Memory-intensive |
Vector Database vs Traditional Database
| Feature | Traditional Database | Vector Database |
|---|---|---|
| Primary Search Method | Exact match | Similarity search |
| Data Representation | Structured rows and columns | High-dimensional vectors |
| Best For | Transactional applications | AI and semantic search systems |
| Query Type | SQL queries | Nearest-neighbor vector queries |
| Optimization | Relational indexing | ANN indexing |
| Semantic Understanding | Limited | Strong |
Alternatives to Vector Databases
| Alternative | Description | Compared to Vector Databases |
|---|---|---|
| Relational Databases | Traditional SQL-based systems. | Better for transactions, worse for semantic retrieval. |
| Search Engines | Keyword-focused retrieval systems. | Strong text search but weaker semantic understanding. |
| Knowledge Graphs | Structured entity relationship databases. | Better reasoning, less scalable for embeddings. |
| In-Memory Caches | Fast temporary storage systems. | Fast but not optimized for vector indexing. |
| Custom ANN Libraries | Standalone nearest-neighbor search libraries. | Fast but lacks full database capabilities. |
Summary
Vector databases are foundational infrastructure for modern AI systems because they enable fast semantic retrieval using embeddings instead of exact keyword matching. They are heavily used in RAG pipelines, recommendation engines, semantic search, and multimodal AI applications. Technologies like Pinecone, FAISS, Weaviate, Milvus, and Qdrant each serve different scalability, deployment, and operational needs. Choosing the right vector database depends on factors such as scale, latency, cloud requirements, metadata filtering, and infrastructure complexity.